Volontaires recherché.e.s
Participer à l’étude « Diagnostiquer un trouble du sommeil à la maison »
Notre chercheur Dr Postuma


Téléchargez la fiche – 9 points pour un plan de gestion des données réussi.
Les trois organismes subventionnaires canadiens (CRSNG, CRSH, IRSC) ont publié en mars 2021 leur Politique des trois organismes sur la gestion des données de recherche qui est basée sur le principe que les données recueillies par la recherche au moyen de fonds publics doivent être gérées de manière responsable et, lorsque possible, être disponibles pour réutilisation. Elle met l’accent sur trois dimensions :
La Politique des trois organismes s’appuie sur la Déclaration de principes des trois organismes sur la gestion des données numériques, publiée au printemps 2016 par les trois grands organismes subventionnaires canadiens (CRSNG, CRSH, IRSC). Son objectif est de promouvoir l’excellence dans la gestion des données générées lors de recherches subventionnées par ces organismes. On y résume les attentes générales en matière de gestion des données de recherche ainsi que le rôle et la responsabilité des chercheurs, des milieux et établissements de recherche ainsi que des bailleurs de fonds dans la satisfaction de celles-ci. Il est important de noter que les trois organismes peuvent avoir en plus de la Politique des politiques spécifiques à chacune d’elles.
De plus, plusieurs organisations ont leurs propres politiques concernant les données de recherche. À Génome Canada, les récipiendaires de fonds doivent s’engager à se conformer aux politiques sur la diffusion et le partage des données. Ainsi, sauf exception, « les équipes de projets financés par Génome Canada doivent partager les données et les ressources sans restrictions et sans tarder ». Plusieurs revues scientifiques imposent le partage des données de recherche comme condition à la publication ou du moins l’encouragent fortement. Dans certains cas, des partenariats ont été développés avec de grands dépôts disciplinaires ou multidisciplinaires et dans d’autres cas, certains périodiques développent leur propre dépôt (exemples : Nature, Elsevier, Springer Nature, Taylor & Francis, Wiley).
Au-delà de ces obligations, la gestion de données de recherche (GDR) contribue à la conduite efficace et responsable de la recherche, accroît la capacité de stockage, de récupération et de réutilisation de ces données et renforce l’excellence de la recherche. Elle est aussi bénéfique aux efforts de collaborations.
Le CIUSSS NÎM reconnaît l’importance de la saine gestion des données en recherche. Puisqu’elle peut être requise par les organismes subventionnaires, qu’elle est fortement recommandée par certains comités d’éthiques et que plusieurs groupes de publication requièrent une gestion de données de recherche exemplaire, il est important pour les membres de la communauté de la recherche au CIUSSS NÎM d’être en mesure de se doter d’un plan de gestion des données. L’objectif du présent guide est donc de fournir les outils requis à l’élaboration de ce plan.
Donnée de recherche
« Les données de la recherche sont définies comme des enregistrements factuels (chiffres, textes, images et sons), qui sont utilisés comme sources principales pour la recherche scientifique et sont généralement reconnus par la communauté scientifique comme nécessaires pour valider des résultats de recherche. » (OCDE, 2007). Exemples: Données d’observation sur le terrain, d’expérimentation en laboratoire, de simulation logicielle, de compilation, résultats de sondage ou d’enquête, interview, etc.
Gestion des données de recherche
La GDR est l’ensemble des processus appliqués pendant un projet de recherche pour gérer la collecte, la documentation, l’entreposage, l’accès et la conservation des données de recherche. Elle intervient donc tout au long du cycle de vie des données. La gestion des données permet de :
Afin d’y arriver, l’élaboration d’un plan de gestion de données est nécessaire.
Plan de gestion des données
Le plan de gestion des données (PGD – Data Management Plan en anglais) aide le chercheur à choisir les meilleures méthodes de gestion de ses données de recherche. Ce document décrit le mode de collecte, de formatage, de conservation et de partage des données. Il facilite le travail des autres chercheurs désirant utiliser les données de recherche en précisant la nature et le mode d’utilisation des données. L’utilisation de ce plan aide aussi le chercheur à déterminer les coûts, les avantages et les défis de la gestion des données de recherche. Le plan de gestion des données doit être adapté et mis à jour au fur et à mesure de l’avancement du projet de recherche. Le format d’un plan de gestion des données et l’ordre des éléments qu’on y trouve peuvent varier grandement. Toutefois, celui-ci devrait décrire :
Principes FAIR
Les principes FAIR (www.go-fair.org/fair-principles) encouragent une meilleure circulation des données de recherche. Les principes FAIR pour la gestion et l’intendance des données scientifiques constituent une pratique exemplaire internationale pour améliorer la récupération, l’accessibilité, la compatibilité et la réutilisation des biens numériques. Les données FAIR sont :
Dès la conception du projet, il est nécessaire d’y intégrer la gestion des données qui seront générées. Ainsi, afin d’éviter des embuches et d’identifier les ressources qui seront nécessaires, il est important de réfléchir dès que possible aux types de données générées, au besoin de gérer des données sensibles, au stockage, à la documentation à produire, au partage éventuel et aux contraintes légales qui seront associés à ces données, entre autres. Comme la gestion des données est évolutive, il est aussi avisé de définir le plus rapidement possible la responsabilité de chaque participant au projet dans celle-ci.
Afin d’aider les membres de la communauté scientifique à réussir cet exercice à multiples facettes, plusieurs outils web sont accessibles sur Internet. Il est recommandé d’utiliser un outil qui respecte les attentes des principaux organismes subventionnaires canadiens.
Assistant PGD
L’Assistant PGD est un outil bilingue d’aide à la rédaction de plan de gestion de données de recherche développé par le Réseau Portage (qui a joint l’Alliance de recherche numérique du Canada), un réseau d’expertise pancanadien fondé par l’Association des bibliothèques de recherche du Canada (ABRC) auquel collaborent, entre autres, Données de Recherche Canada et Calcul Canada. Le résultat peut être exporté en différents formats (PDF, XML et autres). L’outil est disponible gratuitement et est accompagné de tutoriel vidéo : Introduction aux plans de gestion des données, Introduction à l’Assistant PGD, Gérer les plans de gestion de données avec l’Assistant PGD.
Ressources universitaires
Les services de données locaux ou les bibliothécaires universitaires peuvent être contacté pour élaborer un PGD. Ceux-ci mettent normalement à disposition de la documentation explicative (p. ex. UdeM, UQAM, Concordia, ÉTS, UQAC, UdS, UNBC) et mettent à disposition des exemples de PGD. De plus, plusieurs services de bibliothèque offrent des consultations pour identifier les besoins en matière de recherche et de gestion des données.
Formulaire
Le modèle de plan du Réseau Portage peut aussi être complété à partir d’un logiciel comme Microsoft Word en téléchargeant ce formulaire. Plusieurs exemples fictifs sont disponibles.
Autres outils
DMP Online (DCC, Royaume-Uni)
DMP Tool (CDL, États-Unis)
La planification de la gestion des données peut être un processus itératif et il est recommandé de partager un PGD avec les collaborateurs de projet à différentes étapes de la planification. En fonction de l’apprentissage de nouveaux concepts et de l’évolution du projet, il est attendu que le PGD soit mis à jour.
La trame suivante, qui peut également servir de liste de contrôle, mais n’est qu’un modèle proposé, est adaptée du plan de gestion proposé par l’Assistant PGD. Les universités proposent souvent elles aussi une trame type pour aider leur communauté (ex. Université de Montréal). Un plan de gestion de données comprend généralement les éléments suivants :
Les sections ci-bas détaillent les informations associées à chacune de ces sections.
Section 1 : Collecte de données
Il est crucial, dès le début d’un projet, de déterminer si des participants humains seront impliqués et de planifier la gestion des données sensibles. La gestion des données à des fins de recherche doit être conforme à l’Énoncé de politique des trois conseils : Éthique de la recherche avec des êtres humains – 2e édition (EPTC2). Ce document fournit des directives clés sur des aspects tels que le consentement, la protection de la vie privée et de la confidentialité, les droits des peuples autochtones, le contrôle de l’accès aux données confidentielles, l’utilisation des données secondaires et le couplage de données. Les chercheurs collectant des données personnelles doivent respecter la vie privée des participants et assurer la confidentialité des informations recueillies. Les responsables des équipes de recherche sont également tenus de minimiser les risques d’identification des participants et de prévenir les préjudices potentiels liés à la collecte, l’analyse, la diffusion et la conservation des données et des résultats de recherche, conformément aux directives de l’EPTC2. Il est donc essentiel que les chercheurs et leurs équipes comprennent bien les contraintes éthiques, légales et partenariales susceptibles d’affecter leurs projets.
À l’étape de la collecte des données, on doit réfléchir aux types et au format des données qui seront collectées. Différents types de données incluent les données textuelles, numériques, multimédia, des codes de programmations, logiciels, etc. En déterminant le type de données recueillies, cela permettra d’identifier le format dans lequel elles se retrouveront (ex. doc, txt, csv, mp3, avi, bmp, ai, zip, 7z, ppt) et de déterminer comment elles seront lisibles, stockables et transférables. Les formats propriétaires nécessitent parfois des logiciels ou du matériel spécialisé et peuvent ne pas être recommandé. Il est donc préférable de sauvegarder les fichiers dans des formats ouverts (docx, txt, csv, xlsx, mkv) vs fermés (doc, xls, avi).
Il est aussi important de réfléchir à la collecte en elle-même et d’établir comment la collecte sera effectuée. Est-ce que des outils commerciaux seront utilisés? Comment est-ce que l’identité des participants sera protégée? De plus, il est essentiel que les chercheurs consultent les standards de leur domaine pour s’assurer que leurs pratiques sont conformes aux exigences spécifiques. Par ailleurs, on recommande aux chercheurs de vérifier les outils de structuration des données déjà disponibles au sein de leur institution afin de profiter de solutions déjà établies et de standardiser les pratiques au sein de l’organisation, lorsque possible.
Finalement, à cette étape, il est nécessaire d’identifier les méthodes qui seront utilisées pour nommer (nommage), gérer les versions (versionnage) et structurer (organisation) les fichiers afin de mieux les naviguer. Il est important de garder la trace des différentes copies et versions. À noter que ces stratégies ne sont pas seulement essentielles pour une bonne gestion des données de recherche mais elles représentent une méthode de travail efficace pour toutes les personnes impliquées dans la réalisation d’activités de recherche, même si lesdites activités ne visent pas nécessairement à produire un contenu à rendre accessible à la communauté. Voici quelques trucs et conseils pour ces différentes obligations :
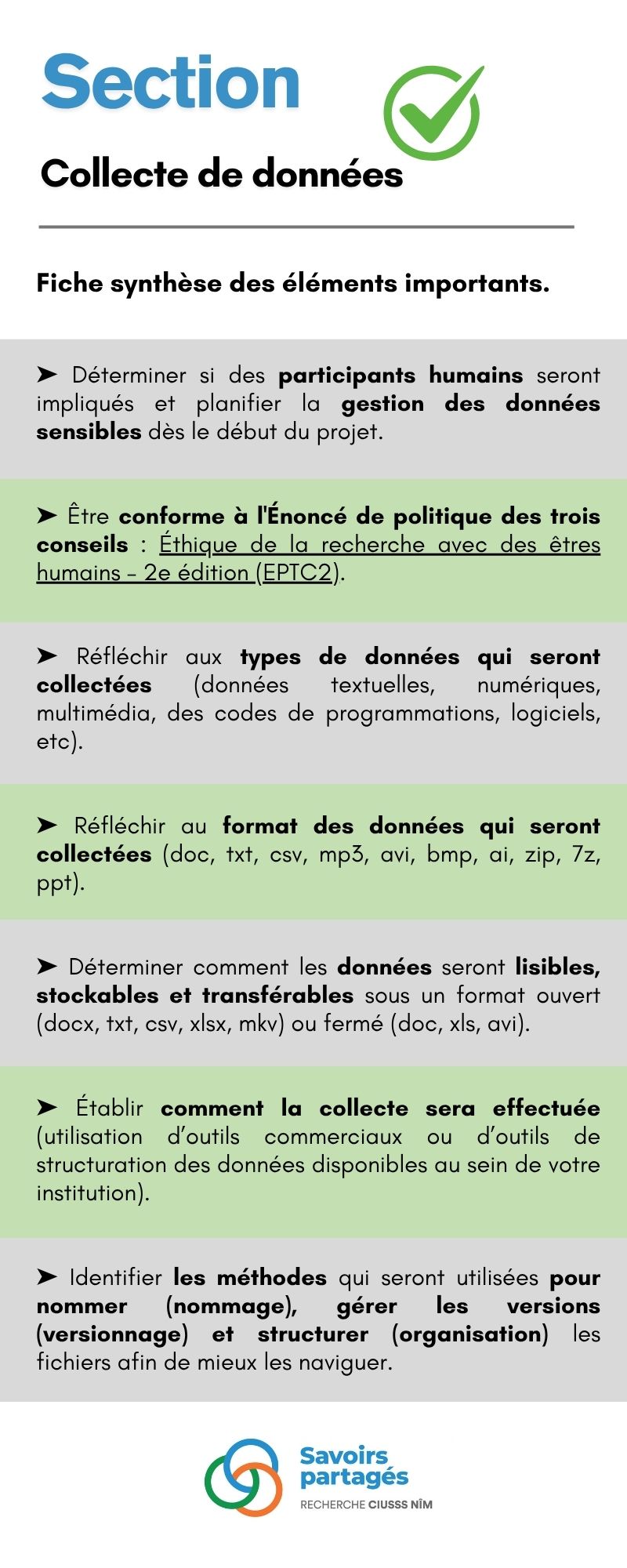
Téléchargez la fiche – Collecte de données – Fiche synthèse.

Téléchargez la fiche – Collecte de données – Trucs et conseils.
Section 2 : Documentation et métadonnées
Pensez aux informations nécessaires pour que les autres puissent comprendre vos données. Par exemple, cela pourrait inclure des renseignements sur l’étude, la description des variables, les sources de données, les processus de transformation et d’analyses de données, les informations sur la confidentialité ou sur l’accès des données et autres informations contextuelles. Encore une fois, un fichier Readme (un par fichier de données idéalement) est une bonne façon de documenter les informations. Finalement, les métadonnées (données sur les données) fournissent les informations de base et décrivent les caractéristiques d’un jeu de données pour bien le comprendre. Par exemple, pour une collection de livre : Auteur, Titre, Date, Langue, etc.
Au besoin, consultez votre bibliothécaire de données universitaire ou l’Alliance de recherche numérique du Canada au sujet des normes et des outils qui faciliteront ce processus. Les questions pertinentes pour cette section incluent :
Il est également important d’identifier les rôles et responsabilités pour la documentation du projet dès le début afin d’en assurer une gestion claire et efficace. La gestion des données de recherche est un processus dynamique et en constante évolution, nécessitant qu’une personne soit imputable pour garantir la bonne conduite du projet.

Téléchargez la fiche – Documentation et métadonnées – Fiche synthèse.
Section 3 : Stockage et sauvegarde
Anticipez vos besoins en matière de stockage de données, les stratégies de sauvegarde des données et la manière dont les données seront consultées et modifiées tout au long du projet. Il est parfois difficile d’évaluer les quantités de stockage requises, il pourrait donc être avisé de contacter le service de Technologie de l’information (TI) de votre institution.
Pour bien sauvegarder les données, la règle du 3-2-1 est souvent mise de l’avant : avoir 3 copies différentes des données, sur au moins 2 supports différents (ordinateur, réseau institutionnel, USB, nuage informatique) et 1 version hors-site. Cette stratégie permet de faire face à différentes situations qui pourraient compromettre les données : corruption d’un fichier, feu, perte, obsolescence technologique, etc. Lorsque l’on sélectionne un moyen de stockage, il est important de considérer le type de données à gérer et les fonctionnalités recherchées. Par exemple, les informations nominatives sur des sujets humains doivent être protégées et ne devraient pas être conservées sur des services infonuagique commerciaux (Dropbox, Google Drive, etc.).
Il est nécessaire de protéger l’accès aux données de recherche. Les principes de bases tel qu’un antivirus et appliquer un mot de posse et un écran de veille automatisé sur les ordinateurs sont de mises. De plus, il faut protéger les données avec un mot de passe ou même chiffrer les données directement sur disque (voir VeraCrypt, Portable PGP, FileVault2). Si les données doivent être partagées, réaliser tout transfert de données sensibles vers l’externe en utilisant un canal de communication chiffré ou en chiffrant les données avant leur envoi. Il est aussi important de mettre en place une procédure de retrait des accès aux données. Finalement, dans le cas des données non-numériques, sécuriser l’accès au local où elles sont conservées.
Questions pertinentes :

Téléchargez la fiche – Stockage et sauvegarde – Fiche synthèse.

Téléchargez la fiche – Stockage et sauvegarde – Trucs et conseils.
Section 4 : Préservation et destruction des données
La préservation des données garantit que les jeux de données peuvent être consultés et compris au fil du temps et tiennent compte des changements technologiques. Il est important de se questionner sur la donnée, d’évaluer les coûts et les bénéfices afin de déterminer lesquelles doivent être conservées : est-ce que la donnée est réutilisable? Doit-elle être conservée pour des raisons juridiques ou politiques? Notez qu’il est important de conserver les données, mais aussi les métadonnées, logiciels et algorithmes. Pour la préservation, il faut favoriser des formats de fichiers ouverts (non propriétaires) de préservation (ZIP, TAR, 7z), inclure une bonne documentation et s’assurer de la confidentialité des sujets de recherche (le cas échéant).
Questions pertinentes :
Quant à la destruction des données, une stratégie pour effacer de manière fiable les données est essentielle. Effacer les fichiers à l’aide des outils d’un système d’exploitation ne détruira pas irrémédiablement les données et certains outils sophistiqués parviennent à récupérer ces données assez facilement. Selon la technologie visée, il est important d’utiliser les outils appropriés, tel que AxCrypt, Eraser et WipeFile pour les disques durs traditionnels, SanDisk SSD, Intel Solid State Toolbox (ou autres outils du fabriquant) pour les disques dur SSD et les lecteurs flash USB.

Téléchargez la fiche – Préservation et destruction des données – Fiche synthèse.

Téléchargez la fiche – Préservation et destruction des données – Trucs et conseils.
Section 5 : Déposer des données
Un dépôt de données est une plateforme où plusieurs ensembles de données sont décrits et hébergés. Cela aide à maximiser la diffusion des résultats de recherche (par exemple, les données ainsi déposées pourraient être cités), facilite la reproductibilité de la recherche et permet le partage des données.
Certaines données sont confidentielles, personnelles ou sensibles, nécessitant un traitement spécifique conforme aux exigences légales et éthiques. La plupart des plateformes demandent que les données soient anonymisées ou dépersonnalisées avant leur téléchargement. Toutefois, il est crucial de noter que la dépersonnalisation peut parfois être insuffisante, car il est possible de ré-identifier une personne à partir de plusieurs données la concernant.
Plusieurs plateformes existent pour diffuser les données et il y a une grande variété de dépôts de données : sans but lucratif, commercial, gouvernemental. Ils peuvent être de type généraliste (Dépôt fédéré de données de recherche, NIH Data Repositories), institutionnel, disciplinaire (GenBANK, PsychData, ICPSR) ou thématique. Les principales universités au Québec mettent à la disposition de leur communauté un dépôt numérique sur la plateforme Boréalis de Scholars Portal. Pour vous aider à sélectionner un dépôt de données, il y a plusieurs critères, incluant le coût, le type de données, la taille des fichiers de données, les licences, la sécurité des données, etc. Il est possible de consulter le bibliothécaire responsable de la gestion des données de recherche de votre université pour établir un choix de dépôt de données.

Téléchargez la fiche – Déposer des données – Fiche synthèse.

Téléchargez la fiche – Déposer des données – Trucs et conseils.
Section 6 : Partage et réutilisation des données
La réutilisation des données par la communauté de recherche permet de sauver du temps, économiser de l’argent, ajouter de la valeur à sa recherche et de réduire la duplication, particulièrement dans les cas de recherche sur l’être humain. Il y a donc des enjeux de temps, d’argent et d’éthique à réutiliser les données et à favoriser le partage des données. Lors de l’élaboration de son plan de gestion de données, il est donc important d’établir quelles données seront partagées et sous quelle forme (brutes, traitées, analysées, définitives) ainsi que de réfléchir aux mesures qui seront prises pour faire connaître l’existence des données. De plus, il existe six différentes licences Creative commons et une licence de domaine public qui permettent la gestion des permissions d’utilisation de données.
Si vous souhaitez à votre tour réutiliser des données d’une autre partie, vous devez vérifier les restrictions de droit d’auteur et de licence, vérifier si les données comportent de renseignements identificatoires sur des êtres humains, valider si une certification éthique ou une loi sur la protection de la vie privée protège ces données et créditer l’auteur original.
Pour trouver des données, il est possible d’utiliser le répertoire de dépôts de données r3data.org, Google Data Search ou un dépôt généraliste (Dépôt fédéré de données de recherche canadiennes, Scholars Portal Dataverse, Dryad, …).

Téléchargez la fiche – Partage et réutilisation des données – Fiche synthèse.
Section 7 : Conformités aux lois et à l’éthique
Les chercheurs qui recueillent des informations personnelles auprès d’individus dans le cadre de leurs recherches ont l’obligation de respecter la vie privée des participants et d’assurer la confidentialité des données. Ainsi, les chercheurs ont la responsabilité de réduire au minimum la possibilité d’identifier les participants à une recherche et les risques de préjudices qu’ils pourraient subir suite à la collecte, l’analyse, la diffusion et la conservation des données et des résultats de recherche (EPTC2).
Qu’est-ce qu’un renseignement personnel ? Au Québec, en vertu de la Loi sur l’accès aux documents des organismes publics et sur la protection des renseignements personnels, les renseignements personnels sont définis comme suit : « sont personnels les renseignements qui concernent une personne physique et permettent de l’identifier » (Art. 54). Également, en vertu de la Loi sur la protection des renseignements personnels dans le secteur privé, « est un renseignement personnel, tout renseignement qui concerne une personne physique et permet de l’identifier » (Art. 2). Tous les renseignements recueillis auprès d’êtres humains ne posent pas nécessairement problème et ne méritent pas la même attention. Les chercheurs doivent avant tout s’assurer de la protection des renseignements identificatoires, c’est-à-dire des informations qui, seules ou mises en relation avec d’autres renseignements, permettent d’identifier une personne en particulier (EPTC2).
Différentes méthodes permettent de protéger la confidentialité des renseignements personnels pour rendre possible un certain partage ou stockage sécurisé de données. La première et la plus simple consiste à supprimer les identifiants directs des données recueillies. Ce processus est généralement appelé anonymisation lorsque la suppression est complète et permanente; les renseignements sont dits anonymisés lorsqu’il n’est plus possible de faire de lien entre l’individu et ses informations identificatoires. On parle plutôt de pseudoanonymisation (ou dénominalisation) lorsque les données identificatoires sont remplacées par des pseudonymes mais sont conservées par le chercheur dans un fichier clé permettant une éventuelle réidentification des participants. Le terme de renseignements anonymes réfère lui à des informations pour lesquelles aucun identificateur n’a jamais été collecté. Plusieurs techniques dites de dépersonnalisation (de-identification) existent (voir également Directives sur la dépersonnalisation des données du Réseau Portage, Canada) :

Téléchargez la fiche – Conformités aux lois et à l’éthique – Fiche synthèse.
Réseau Portage :
Ressources Gouvernement du Canada
Guides universitaires
Nommage de fichiers
Delengaigne, X., Mongin, P. et Deschamps, C. (2011). Organisez vos données personnelles : l’essentiel du personal knowledge management. Paris : Eyrolles : Éditions d’Organisation.
Lecomte, B., Couture, M. et UQAM. Service des archives et de gestion des documents. (Janvier 2017). Bonne pratiques de gestion des documents électroniques. Formation offerte au personnel de l’UQAM par le Service des archives et de gestion des documents.
Morlanne-Fendan, P. et Tanti, M. (2013). Nommage de documents électroniques : mise au point et évaluation d’une procédure. Documentation et bibliothèques, 59(2), 82-90. DOI: 10.7202/1033220ar
Bibliothèque et Archives Canada. (2014). Lignes directrices sur les formats de fichier à utiliser pour transférer des ressources documentaires.